Así funcionan los más recientes algoritmos de compresión para conseguir vídeos menos pesados, pero con calidad

Los contenidos de vídeo se han convertido en elementos más que habituales en el trabajo diario con nuestros PCs de sobremesa o dispositivos móviles, por lo que en estos momentos podemos echar mano de una buena cantidad de formatos y tipos de fichero de este tipo, dependiendo de hacia dónde vayan dirigidos.
Y es que hay que tener en cuenta que aquí es donde entran en juego los importantes algoritmos de compresión de vídeo, ya que con el paso de los años han ido evolucionando en gran medida para mejorar su funcionalidad debido, entre otras cosas, a su extendido uso. Para ello, lo que se hace internamente es aplicar diferentes técnicas matemáticas y lógicas al archivo de vídeo como tal, todo con el fin de reducir su tamaño y mantener la calidad del vídeo en la medida de lo posible.
Es por ello que, para que nos hagamos una idea, vamos a ver cómo se llevan a cabo las tareas de compresión de vídeos en un estándar tan usado hoy día como es el H.264. Para empezar diremos que los entre otras cosas, los algoritmos de compresión de vídeo buscan redundancias en el contenido, por lo que al codificar datos redundantes un número mínimo de veces, se puede reducir el tamaño del archivo final. Por ejemplo, si en una escena de un minuto la cara de un personaje cambia lentamente de expresión, no tiene sentido codificar la imagen para cada fotograma, por lo que se codifica una vez y se vuelve a usar hasta que se produzcan cambios significativos en el vídeo.
Para entender mejor el proceso, debemos distinguir entre los fotogramas “I”, “P” y “B”, donde los “I” son aquellos que están completamente codificados, por lo que cada uno de estos fotogramas contienen todos los datos necesarios para representar una imagen. Por otro lado los “P” se predicen en función de cómo cambia la imagen desde el último fotograma “I” codificado, mientras que los “B” se predicen bidireccionalmente, utilizando los datos tanto del último fotograma “P” como del siguiente “I”. De este modo los fotogramas “P” tan sólo necesitan almacenar la información visual que es exclusiva del mismo.
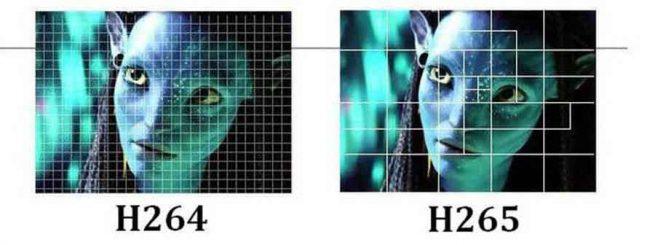
Cómo se comprimen los actuales vídeos que vemos a diario
Al mismo tiempo, el algoritmo tiene una «idea» de dónde comienza la imagen, lo que se corresponde con el primer fotograma “I”, y dónde termina, segundo fotograma “I”, por lo que usa datos parciales para codificar dejando fuera todos los píxeles estáticos redundantes que no son necesarios para crear la imagen resultante comprimida. Además también hay que saber que los fotogramas “I” se comprimen de forma independiente, del mismo modo que se guardan las imágenes fijas, ya que debido a que estos no utilizan datos predictivos, la imagen comprimida contiene todos los datos utilizados para mostrar este mismo fotograma.
Eso sí, todavía están comprimidos por un algoritmo de compresión de imagen similar al JPEG, por lo que esta codificación tiene lugar normalmente en el espacio de color YCbCr, que separa los datos de luminosidad de los datos de color permitiendo así que los cambios de movimiento y color se codifiquen por separado. Por otro lado, si nos referimos a los códecs no predictivos como DV o Motion JPEG, la única compresión que se puede lograr es comprimir la imagen de un solo fotograma, que aunque menos eficiente, la calidad es superior.

Sin embargo, en los códecs predictivos como el mencionado H.264, los fotogramas “I” se muestran periódicamente para refrescar el flujo de datos, por lo que cuanto más separados estén estos frames, más pequeño será el archivo de vídeo resultante. Pero tampoco pueden estar muy separados, ya que la precisión que la compresión obtiene de los fotogramas predictivos se degradará afectando a la calidad del resultado.
Por tanto podemos deducir que los codificadores de vídeo intentan «predecir» el cambio de un fotograma al siguiente, por lo que cuanto más cerca estén sus predicciones, más efectivo será el algoritmo de compresión, que es lo se crea en los fotogramas “P” y “B”.